We are excited to announce the release of PyTorch 1.12 (release note)! This release is composed of over 3124 commits, 433 contributors. Along with 1.12, we are releasing beta versions of AWS S3 Integration, PyTorch Vision Models on Channels Last on CPU, Empowering PyTorch on Intel® Xeon® Scalable processors with Bfloat16 and FSDP API. We want to sincerely thank our dedicated community for your contributions.
Summary:
- Functional APIs to functionally apply module computation with a given set of parameters
- Complex32 and Complex Convolutions in PyTorch
- DataPipes from TorchData fully backward compatible with DataLoader
- functorch with improved coverage for APIs
- nvFuser a deep learning compiler for PyTorch
- Changes to float32 matrix multiplication precision on Ampere and later CUDA hardware
- TorchArrow, a new beta library for machine learning preprocessing over batch data
Frontend APIs
Introducing TorchArrow
We’ve got a new Beta release ready for you to try and use: TorchArrow. This is a library for machine learning preprocessing over batch data. It features a performant and Pandas-style, easy-to-use API in order to speed up your preprocessing workflows and development.
Currently, it provides a Python DataFrame interface with the following features:
- High-performance CPU backend, vectorized and extensible User-Defined Functions (UDFs) with Velox
- Seamless handoff with PyTorch or other model authoring, such as Tensor collation and easily plugging into PyTorch DataLoader and DataPipes
- Zero copy for external readers via Arrow in-memory columnar format
For more details, please find our 10-min tutorial, installation instructions, API documentation, and a prototype for data preprocessing in TorchRec.
(Beta) Functional API for Modules
PyTorch 1.12 introduces a new beta feature to functionally apply Module computation with a given set of parameters. Sometimes, the traditional PyTorch Module usage pattern that maintains a static set of parameters internally is too restrictive. This is often the case when implementing algorithms for meta-learning, where multiple sets of parameters may need to be maintained across optimizer steps.
The new torch.nn.utils.stateless.functional_call() API allows for:
- Module computation with full flexibility over the set of parameters used
- No need to reimplement your module in a functional way
- Any parameter or buffer present in the module can be swapped with an externally-defined value for use in the call. Naming for referencing parameters / buffers follows the fully-qualified form in the module’s
state_dict()
Example:
import torch
from torch import nn
from torch.nn.utils.stateless import functional_call
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(3, 3)
self.bn = nn.BatchNorm1d(3)
self.fc2 = nn.Linear(3, 3)
def forward(self, x):
return self.fc2(self.bn(self.fc1(x)))
m = MyModule()
# Define parameter / buffer values to use during module computation.
my_weight = torch.randn(3, 3, requires_grad=True)
my_bias = torch.tensor([1., 2., 3.], requires_grad=True)
params_and_buffers = {
'fc1.weight': my_weight,
'fc1.bias': my_bias,
# Custom buffer values can be used too.
'bn.running_mean': torch.randn(3),
}
# Apply module computation to the input with the specified parameters / buffers.
inp = torch.randn(5, 3)
output = functional_call(m, params_and_buffers, inp)
(Beta) Complex32 and Complex Convolutions in PyTorch
PyTorch today natively supports complex numbers, complex autograd, complex modules, and numerous complex operations, including linear algebra and Fast Fourier Transform (FFT) operators. Many libraries, including torchaudio and ESPNet, already make use of complex numbers in PyTorch, and PyTorch 1.12 further extends complex functionality with complex convolutions and the experimental complex32 (“complex half”) data type that enables half precision FFT operations. Due to the bugs in CUDA 11.3 package, we recommend using CUDA 11.6 package from wheels if you are using complex numbers.
(Beta) Forward-mode Automatic Differentiation
Forward-mode AD allows the computation of directional derivatives (or equivalently, Jacobian-vector products) eagerly in the forward pass. PyTorch 1.12 significantly improves the operator coverage for forward-mode AD. See our tutorial for more information.
TorchData
BC DataLoader + DataPipe
`DataPipe` from TorchData becomes fully backward compatible with the existing `DataLoader` regarding shuffle determinism and dynamic sharding in both multiprocessing and distributed environments. For more details, please check out the tutorial.
(Beta) AWS S3 Integration
DataPipes based on AWSSDK have been integrated into TorchData. It provides the following features backed by native AWSSDK:
- Retrieve list of urls from each S3 bucket based on prefix
- Support timeout to prevent hanging indefinitely
- Support to specify S3 bucket region
- Load data from S3 urls
- Support buffered and multi-part download
- Support to specify S3 bucket region
AWS native DataPipes are still in the beta phase. And, we will keep tuning them to improve their performance.
(Prototype) DataLoader2
DataLoader2 became available in prototype mode. We are introducing new ways to interact between DataPipes, DataLoading API, and backends (aka ReadingServices). Feature is stable in terms of API, but functionally not complete yet. We welcome early adopters and feedback, as well as potential contributors.
For more details, please checkout the link.
functorch
Inspired by Google JAX, functorch is a library that offers composable vmap (vectorization) and autodiff transforms. It enables advanced autodiff use cases that would otherwise be tricky to express in PyTorch. Examples of these include:
- running ensembles of models on a single machine
- efficiently computing Jacobians and Hessians
- computing per-sample-gradients (or other per-sample quantities)
We’re excited to announce functorch 0.2.0 with a number of improvements and new experimental features.
Significantly improved coverage
We significantly improved coverage for functorch.jvp (our forward-mode autodiff API) and other APIs that rely on it (functorch.{jacfwd, hessian}).
(Prototype) functorch.experimental.functionalize
Given a function f, functionalize(f) returns a new function without mutations (with caveats). This is useful for constructing traces of PyTorch functions without in-place operations. For example, you can use make_fx(functionalize(f)) to construct a mutation-free trace of a pytorch function. To learn more, please see the documentation.
For more details, please see our installation instructions, documentation, tutorials, and release notes.
Performance Improvements
Introducing nvFuser, a deep learning compiler for PyTorch
In PyTorch 1.12, Torchscript is updating its default fuser (for Volta and later CUDA accelerators) to nvFuser, which supports a wider range of operations and is faster than NNC, the previous fuser for CUDA devices. A soon to be published blog post will elaborate on nvFuser and show how it speeds up training on a variety of networks.
See the nvFuser documentation for more details on usage and debugging.
Changes to float32 matrix multiplication precision on Ampere and later CUDA hardware
PyTorch supports a variety of “mixed precision” techniques, like the torch.amp (Automated Mixed Precision) module and performing float32 matrix multiplications using the TensorFloat32 datatype on Ampere and later CUDA hardware for faster internal computations. In PyTorch 1.12 we’re changing the default behavior of float32 matrix multiplications to always use full IEEE fp32 precision, which is more precise but slower than using the TensorFloat32 datatype for internal computation. For devices with a particularly high ratio of TensorFloat32 to float32 throughput such as A100, this change in defaults can result in a large slowdown.
If you’ve been using TensorFloat32 matrix multiplications then you can continue to do so by setting torch.backends.cuda.matmul.allow_tf32 = True
which is supported since PyTorch 1.7. Starting in PyTorch 1.12 the new matmul precision API can be used, too: torch.set_float32_matmul_precision(“highest”|”high”|”medium”)
To reiterate, PyTorch’s new default is “highest” precision for all device types. We think this provides better consistency across device types for matrix multiplications. Documentation for the new precision API can be found here. Setting the “high” or “medium” precision types will enable TensorFloat32 on Ampere and later CUDA devices. If you’re updating to PyTorch 1.12 then to preserve the current behavior and faster performance of matrix multiplications on Ampere devices, set precision to “high”.
Using mixed precision techniques is essential for training many modern deep learning networks efficiently, and if you’re already using torch.amp this change is unlikely to affect you. If you’re not familiar with mixed precision training then see our soon to be published “What Every User Should Know About Mixed Precision Training in PyTorch” blogpost.
(Beta) Accelerating PyTorch Vision Models with Channels Last on CPU
Memory formats have a significant impact on performance when running vision models, generally Channels Last is more favorable from a performance perspective due to better data locality. 1.12 includes fundamental concepts of memory formats and demonstrates performance benefits using Channels Last on popular PyTorch vision models on Intel® Xeon® Scalable processors.
- Enables Channels Last memory format support for the commonly used operators in CV domain on CPU, applicable for both inference and training
- Provides native level optimization on Channels Last kernels from ATen, applicable for both AVX2 and AVX512
- Delivers 1.3x to 1.8x inference performance gain over Channels First for TorchVision models on Intel® Xeon® Ice Lake (or newer) CPUs
(Beta) Empowering PyTorch on Intel® Xeon® Scalable processors with Bfloat16
Reduced precision numeric formats like bfloat16 improves PyTorch performance across multiple deep learning training workloads. PyTorch 1.12 includes the latest software enhancements on bfloat16 which applies to a broader scope of user scenarios and showcases even higher performance gains. The main improvements include:
- 2x hardware compute throughput vs. float32 with the new bfloat16 native instruction VDPBF16PS, introduced on Intel® Xeon® Cooper Lake CPUs
- 1/2 memory footprint of float32, faster speed for memory bandwidth intensive operators
- 1.4x to 2.2x inference performance gain over float32 for TorchVision models on Intel® Xeon® Cooper Lake (or newer) CPUs
(Prototype) Introducing Accelerated PyTorch Training on Mac
With the PyTorch 1.12 release, developers and researchers can now take advantage of Apple silicon GPUs for significantly faster model training. This unlocks the ability to perform machine learning workflows like prototyping and fine-tuning locally, right on Mac. Accelerated GPU training is enabled using Apple’s Metal Performance Shaders (MPS) as a backend. The benefits include performance speedup from accelerated GPU training and the ability to train larger networks or batch sizes locally. Learn more here.
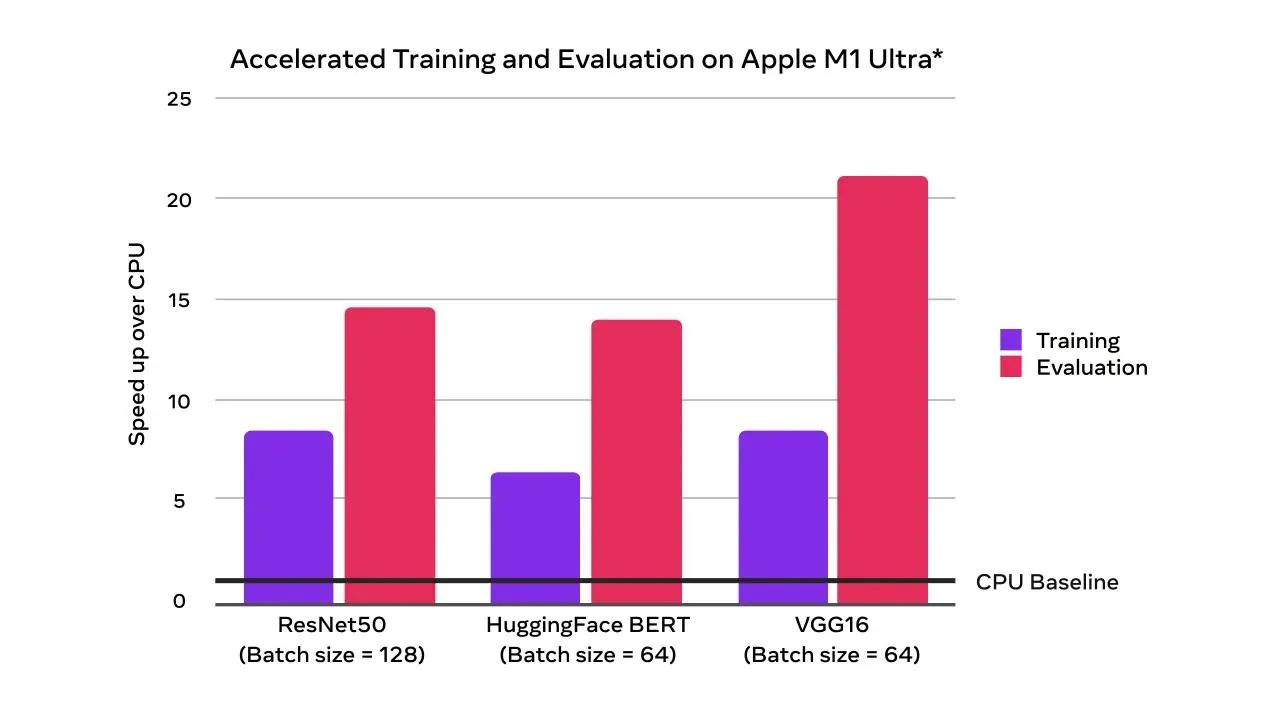
Accelerated GPU training and evaluation speedups over CPU-only (times faster)
Alongside the new MPS device support, the M1 binaries for Core and Domain libraries that have been available for the last few releases are now an official prototype feature. These binaries can be used to run PyTorch natively on Apple Silicon.
(Prototype) BetterTransformer: Fastpath execution for Transformer Encoder Inference
PyTorch now supports CPU and GPU fastpath implementations (“BetterTransformer”) for several Transformer Encoder modules including TransformerEncoder, TransformerEncoderLayer, and MultiHeadAttention (MHA). The BetterTransformer fastpath architecture Better Transformer is consistently faster – 2x for many common execution scenarios, depending on model and input characteristics. The new BetterTransformer-enabled modules are API compatible with previous releases of the PyTorch Transformer API and will accelerate existing models if they meet fastpath execution requirements, as well as read models trained with previous versions of PyTorch. PyTorch 1.12 includes:
- BetterTransformer integration for Torchtext’s pretrained RoBERTa and XLM-R models
- Torchtext which builds on the PyTorch Transformer API
- Fastpath execution for improved performance by reducing execution overheads with fused kernels which combines multiple operators into a single kernel
- Option to achieve additional speedups by taking advantage of data sparsity during the processing of padding tokens in natural-language processing (by setting enable_nested_tensor=True when creating a TransformerEncoder)
- Diagnostics to help users understand why fastpath execution did not occur
![]()
Distributed
(Beta) Fully Sharded Data Parallel (FSDP) API
FSDP API helps easily scale large model training by sharding a model’s parameters, gradients and optimizer states across data parallel workers while maintaining the simplicity of data parallelism. The prototype version was released in PyTorch 1.11 with a minimum set of features that helped scaling tests of models with up to 1T parameters.
In this beta release, FSDP API added the following features to support various production workloads. Highlights of the the newly added features in this beta release include:
- Universal sharding strategy API - Users can easily change between sharding strategies with a single line change, and thus compare and use DDP (only data sharding), FSDP (full model and data sharding), or Zero2 (only sharding of optimizer and gradients) to optimize memory and performance for their specific training needs
- Fine grained mixed precision policies - Users can specify a mix of half and full data types (bfloat16, fp16 or fp32) for model parameters, gradient communication, and buffers via mixed precision policies. Models are automatically saved in fp32 to allow for maximum portability
- Transformer auto wrapping policy - allows for optimal wrapping of Transformer based models by registering the models layer class, and thus accelerated training performance
- Faster model initialization using device_id init - initialization is performed in a streaming fashion to avoid OOM issues and optimize init performance vs CPU init
- Rank0 streaming for full model saving of larger models - Fully sharded models can be saved by all GPU’s streaming their shards to the rank 0 GPU, and the model is built in full state on the rank 0 CPU for saving
For more details and example code, please checkout the documentation and the tutorial.
Thanks for reading, If you’re interested in these updates and want to join the PyTorch community, we encourage you to join the discussion forums and open GitHub issues. To get the latest news from PyTorch, follow us on Twitter, Medium, YouTube, and LinkedIn.
Cheers!
Team PyTorch
