
import torch
tacotron2 = torch.hub.load('nvidia/DeepLearningExamples:torchhub', 'nvidia_tacotron2')
will load the Tacotron2 model pre-trained on LJ Speech dataset
Model Description
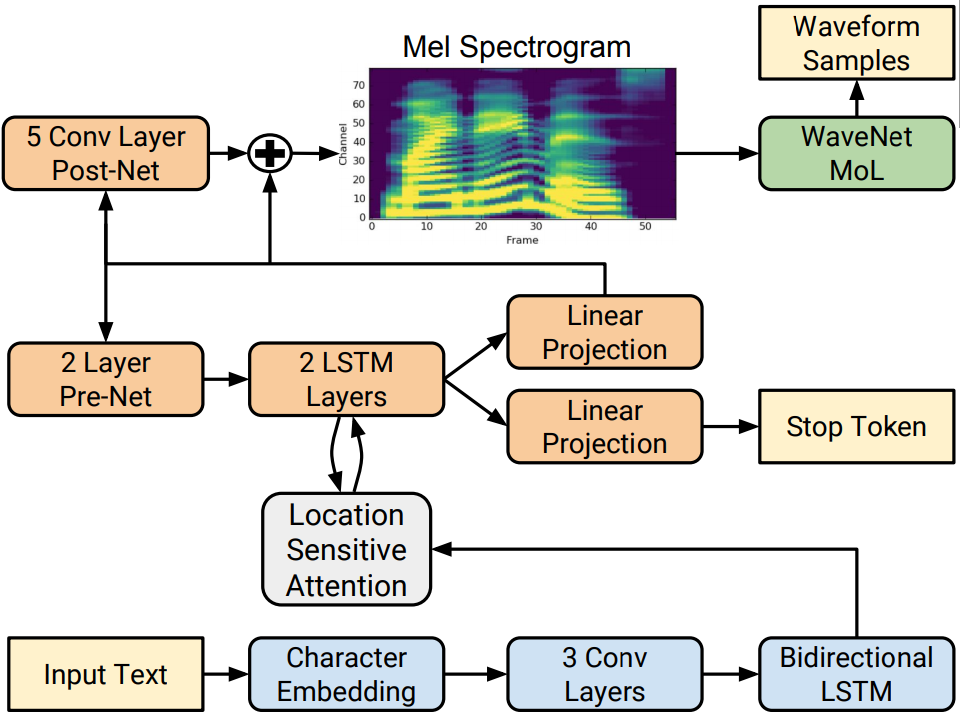
The Tacotron 2 and WaveGlow model form a text-to-speech system that enables user to synthesise a natural sounding speech from raw transcripts without any additional prosody information. The Tacotron 2 model produces mel spectrograms from input text using encoder-decoder architecture. WaveGlow (also available via torch.hub) is a flow-based model that consumes the mel spectrograms to generate speech.
This implementation of Tacotron 2 model differs from the model described in the paper. Our implementation uses Dropout instead of Zoneout to regularize the LSTM layers.
Example
In the example below:
- pretrained Tacotron2 and Waveglow models are loaded from torch.hub
- Tacotron2 generates mel spectrogram given tensor represantation of an input text (“Hello world, I missed you”)
- Waveglow generates sound given the mel spectrogram
- the output sound is saved in an ‘audio.wav’ file
To run the example you need some extra python packages installed. These are needed for preprocessing the text and audio, as well as for display and input / output.
pip install numpy scipy librosa unidecode inflect librosa
import numpy as np
from scipy.io.wavfile import write
Prepare tacotron2 for inference
tacotron2 = tacotron2.to('cuda')
tacotron2.eval()
Load waveglow from PyTorch Hub
waveglow = torch.hub.load('nvidia/DeepLearningExamples:torchhub', 'nvidia_waveglow')
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to('cuda')
waveglow.eval()
Now, let’s make the model say “hello world, I missed you”
text = "hello world, I missed you"
Now chain pre-processing -> tacotron2 -> waveglow
# preprocessing
sequence = np.array(tacotron2.text_to_sequence(text, ['english_cleaners']))[None, :]
sequence = torch.from_numpy(sequence).to(device='cuda', dtype=torch.int64)
# run the models
with torch.no_grad():
_, mel, _, _ = tacotron2.infer(sequence)
audio = waveglow.infer(mel)
audio_numpy = audio[0].data.cpu().numpy()
rate = 22050
You can write it to a file and listen to it
write("audio.wav", rate, audio_numpy)
Alternatively, play it right away in a notebook with IPython widgets
from IPython.display import Audio
Audio(audio_numpy, rate=rate)
Details
For detailed information on model input and output, training recipies, inference and performance visit: github and/or NGC
References
- Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
- WaveGlow: A Flow-based Generative Network for Speech Synthesis
- Tacotron2 and WaveGlow on NGC
- Tacotron2 and Waveglow on github
